
Learn what system scalability really means for SaaS companies. Explore scaling strategies, common bottlenecks, and best practices for building infrastructure that grows with your business.
Most SaaS leaders think scalability means handling more users. That’s only part of the story. True system scalability ensures your infrastructure maintains predictable performance, reliability, and cost efficiency as load, data volume, and operational complexity increase. This guide breaks down what scalability really means for growth-stage SaaS companies, explores common bottlenecks that derail scaling efforts, and provides actionable strategies to build infrastructure that grows with your business without breaking your budget or your team.
Key takeaways
| Point | Details |
|---|---|
| Scalability is multidimensional | It includes load capacity, data volume, complexity management, and cost control, not just user growth. |
| Database and visibility gaps are primary blockers | Poor observability and database contention cause most scaling failures in SaaS systems. |
| Horizontal scaling beats vertical for resilience | Adding servers improves fault tolerance and availability better than upgrading single machines. |
| Observability enables proactive scaling | Centralized logging and metrics let teams detect issues before customers experience problems. |
| Early architectural decisions prevent costly rewrites | Strategic planning around modularity and async processing saves significant technical debt later. |
Understanding system scalability: definition and scope
When SaaS leaders hear scalability, they often picture adding more users to their platform. That narrow view misses the bigger picture. System scalability maintains predictable performance and reliability as load, data, and complexity increase without your cost curve going vertical. This definition shifts focus from simple capacity to sustainable growth.
Scalability operates across multiple dimensions in SaaS environments. You need to handle more tenants, increased data per tenant, higher requests per second, improved uptime guarantees, and controlled cost per user. Each dimension creates unique pressure points. A system that scales beautifully for user count might collapse under data volume growth. Another might handle traffic spikes but become prohibitively expensive at scale.
Common bottlenecks emerge predictably. Databases struggle under concurrent writes. Application servers hit memory limits. Network bandwidth saturates. Storage costs balloon. These technical constraints interact with operational challenges like deployment speed, monitoring gaps, and team coordination overhead. The result? Systems that worked fine at 100 users break catastrophically at 10,000.
Early architectural decisions determine your scaling trajectory. Choices about data modeling, service boundaries, caching strategies, and async processing patterns lock in constraints or enable flexibility. Teams that treat scalability as an afterthought face expensive rewrites. Those who plan strategically build systems that adapt as requirements evolve.
Pro Tip: Map your current bottlenecks across all dimensions before investing in scaling solutions. You might discover your real constraint isn’t servers but database query patterns or deployment pipelines.
Understanding these fundamentals helps you evaluate your backend architecture against real scaling requirements. The next section examines specific challenges that trip up even well-designed systems.
Common scalability challenges in SaaS systems
Database bottlenecks top the list of scaling killers. As your user base grows, concurrent reads and writes create contention. Poorly optimized queries that ran fine with 1,000 records grind to a halt at 100,000. Index strategies that worked initially become liabilities. Connection pool exhaustion causes cascading failures. Database contention and inefficient queries consistently emerge as primary scaling hurdles in production systems.

Operational visibility gaps cause teams to scale blindly. Without centralized logging and metrics, you can’t identify which component is actually struggling. Is it the application server, the database, or network latency? Teams make scaling decisions based on guesses rather than data. They add servers when they need better caching. They upgrade databases when the real issue is unoptimized queries. This trial and error approach wastes time and money.
Manual deployments and tightly coupled services slow your ability to respond to scaling needs. When deploying a fix requires coordinating multiple teams and downtime windows, you can’t iterate quickly. Tightly coupled architectures mean a change in one service breaks three others. This brittleness makes teams risk-averse, delaying necessary scaling work until problems become critical.
Request path timing and asynchronous backlogs degrade performance under load. Synchronous operations that take 200ms at low traffic balloon to 5 seconds under peak load. Background job queues fill up faster than workers can process them. Users see timeouts and errors. Your system appears to fail randomly because the real bottleneck is invisible in your monitoring.
Common errors compound these technical challenges. Teams scale too late, after customers already experience problems. They scale without complete data, guessing at solutions. They optimize the wrong layer, adding application servers when the database is the constraint. They neglect asynchronous processing, forcing every operation to complete synchronously.
Pro Tip: Invest in automated deployments and observability tools before you need them. The cost of implementing these foundations is trivial compared to debugging scaling issues in production without proper instrumentation.
These challenges directly impact your team’s workflow efficiency and your ability to maintain service quality. Understanding them prepares you to evaluate scaling strategies effectively. The patterns are consistent across SaaS companies, which means solutions are well understood. You don’t need to reinvent approaches, just apply proven strategies to your specific context.
Recognizing your current challenges lets you prioritize scaling investments. Maybe you need better backend architecture patterns. Perhaps observability is your gap. Or your deployment process needs automation. Each challenge has targeted solutions.
Key scalability strategies: vertical scaling, horizontal scaling, and modular architecture
Vertical scaling means upgrading a single machine’s resources. You add more CPU, RAM, or faster storage to your existing server. This approach is straightforward. No architectural changes required. No distributed system complexity. You simply provision a bigger box and migrate your workload. For many SaaS applications, vertical scaling solves immediate capacity constraints with minimal engineering effort.
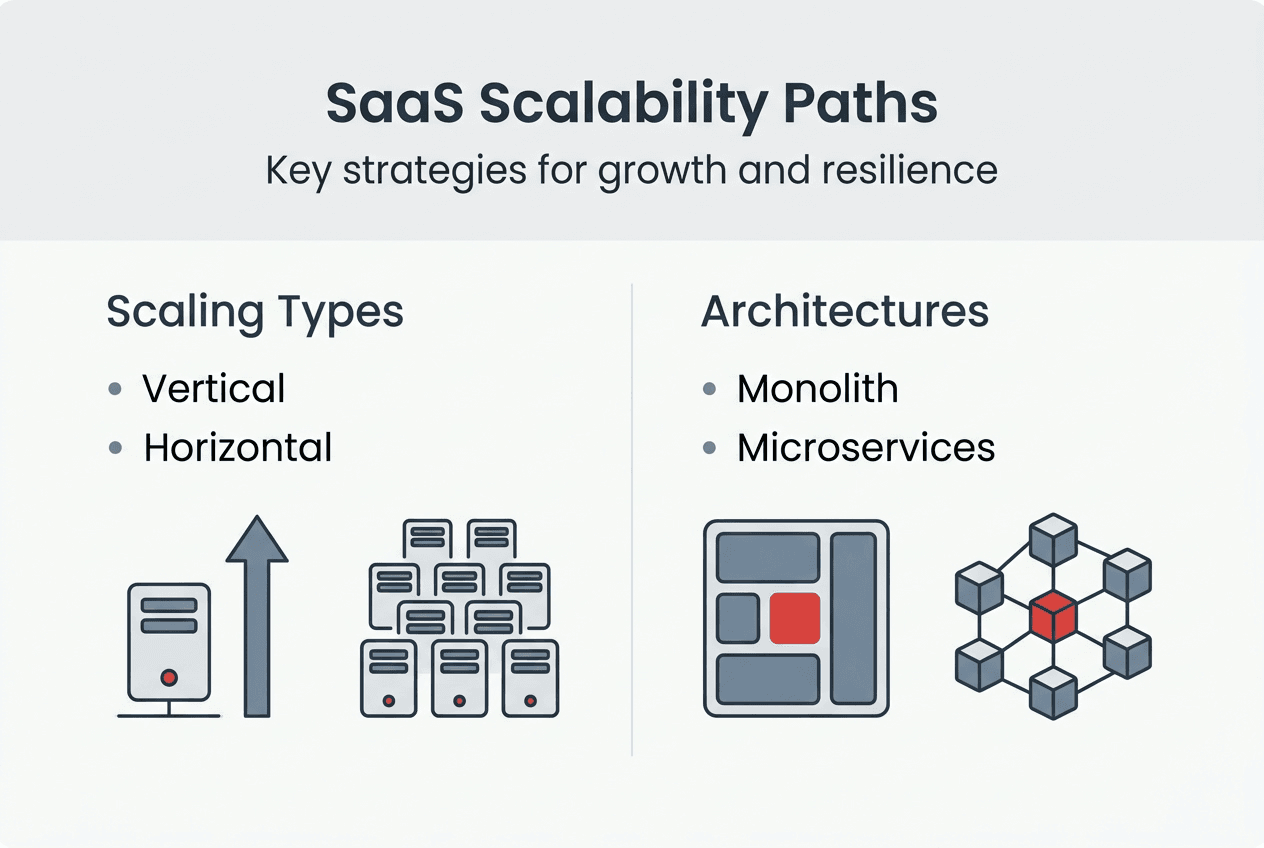
Horizontal scaling distributes load across multiple machines. Instead of one powerful server, you run many smaller servers behind a load balancer. Each handles a portion of traffic. This approach fundamentally changes your architecture. You need stateless application design, distributed data management, and coordination between instances. The complexity increases, but so does your ceiling for growth.
Horizontal scaling improves fault tolerance, performance, and availability compared to vertical approaches. When one server fails, others continue serving traffic. You can deploy updates with zero downtime by rolling changes across instances. Geographic distribution becomes possible, reducing latency for global users. The tradeoffs favor horizontal scaling for most SaaS applications beyond early stage.
| Approach | Pros | Cons | | — | — | | Vertical Scaling | Simple implementation, no architecture changes, lower operational complexity | Hardware limits, single point of failure, downtime during upgrades, diminishing returns at high specs | | Horizontal Scaling | Unlimited growth potential, fault tolerance, zero-downtime deploys, geographic distribution | Complex architecture, distributed system challenges, higher operational overhead, session management complexity |
Vertical scaling works best when your bottleneck is straightforward and uptime requirements are modest. Early-stage SaaS companies often start here. The simplicity lets you focus on product development rather than infrastructure. But recognize the ceiling. Eventually, hardware limits or availability requirements force a transition to horizontal approaches.
Modular monoliths offer a pragmatic starting point. Start with a modular monolith before jumping into microservices. You organize code into clear modules with defined boundaries, but deploy everything together. This gives you flexibility to extract services later without the operational overhead of distributed systems from day one. Most SaaS companies benefit from this middle ground.
Microservices represent the advanced scaling strategy. You split your application into independent services, each with its own database and deployment cycle. Teams can scale services independently based on their specific load patterns. The authentication service might need different scaling than the reporting service. This granular control optimizes resource usage and team autonomy.
Pro Tip: Evaluate your actual bottleneck before choosing a scaling approach. If database queries are slow, adding application servers won’t help. If you’re CPU-bound on a single operation, horizontal scaling might not distribute load effectively. Match your strategy to your constraint.
These architectural patterns connect directly to your backend architecture decisions. The right choice depends on your current scale, growth trajectory, and team capabilities. Understanding the tradeoffs lets you make informed decisions rather than following trends.
For deeper technical comparisons, explore resources on horizontal versus vertical scaling and architectural tradeoffs. These provide implementation details beyond strategic considerations.
Your CMS and content tools also need scaling consideration. As content volume grows, the systems managing it face similar constraints. Applying these same principles to your content infrastructure prevents bottlenecks in your editorial workflow.
Best practices for scalable SaaS infrastructure and observability
Centralized logging and metrics tracking form the foundation of scalable systems. You need a single place to query logs across all services. Metrics should flow to a unified dashboard showing request rates, error rates, latency percentiles, and resource utilization. Without this visibility, you’re flying blind. Every scaling decision becomes guesswork.
Performance monitoring and alerting enable proactive issue detection. Set thresholds for key metrics like response time, error rate, and queue depth. When metrics cross thresholds, alerts notify the team before customers report problems. This shifts you from reactive firefighting to proactive optimization. You fix issues during business hours instead of 3am emergencies.
Caching frequently accessed data reduces database load and improves response time. Implement caching at multiple levels. Browser caching for static assets. CDN caching for content. Application-level caching for computed results. Database query caching for expensive operations. Each layer reduces load on downstream systems. A well-designed caching strategy can reduce database queries by 80% or more.
Message queues for asynchronous processing improve user experience and system stability under load. Don’t make users wait for operations that can happen in the background. Send emails asynchronously. Process uploaded files in workers. Generate reports offline. Queue-based architectures let you scale worker capacity independently from web servers. They also provide natural backpressure when load spikes.
Practical steps for scaling infrastructure efficiently:
- Implement health check endpoints on all services for automated monitoring
- Use connection pooling to optimize database resource usage
- Deploy behind a load balancer even with a single server to enable future horizontal scaling
- Separate read and write database connections to optimize query routing
- Implement rate limiting to protect against traffic spikes and abuse
- Use feature flags to roll out changes gradually and reduce deployment risk
Building an observability pipeline for SaaS:
- Instrument your application code with structured logging that includes request IDs and user context
- Configure centralized log aggregation using tools like ELK stack or managed services
- Set up metrics collection for application, database, and infrastructure components
- Create dashboards showing key business and technical metrics in one view
- Define alerting rules with appropriate thresholds and escalation paths
- Implement distributed tracing to understand request flows across services
- Schedule regular reviews of metrics to identify trends before they become problems
Automated deployments reduce coupling and improve agility. Continuous integration pipelines run tests automatically. Deployment scripts eliminate manual steps and reduce errors. Blue-green deployments enable instant rollbacks. These practices let you ship changes confidently and frequently. Fast deployment cycles mean you can respond to scaling issues quickly.
Prioritize operational visibility to avoid late scaling decisions. Many teams wait until systems are failing before investing in observability. By then, you’re debugging production issues without proper tools. Build monitoring into your initial architecture. The investment pays dividends immediately and compounds as you grow.
These practices directly support your team’s workflow efficiency. Better observability means faster debugging. Asynchronous processing means smoother user experiences. Automated deployments mean less time on operations and more on features.
Your content management systems benefit from these same principles. Caching content reduces database load. Asynchronous publishing workflows improve editor experience. Monitoring content performance helps optimize your strategy. Scalability thinking applies across your entire SaaS infrastructure.
Scale your SaaS system with expert guidance
Understanding system scalability is just the first step. Implementing these strategies in your specific context requires experience with backend architecture, infrastructure design, and operational best practices. Rule27 Design specializes in building scalable administrative systems and digital infrastructure for growth-stage SaaS companies.
We’ve helped companies implement horizontal scaling patterns, optimize database performance, and build observability pipelines that provide real-time insights into system health. Our approach combines technical architecture expertise with deep understanding of business operations. We don’t just add servers, we design systems that improve workflow efficiency and support your growth trajectory.
Explore our backend architecture guide for deeper technical insights. Or visit Rule27 Design to learn how we can help you build infrastructure that scales with your ambitions.
“The best time to plan for scale is before you need it. The second best time is now.”
Frequently asked questions
What are the main differences between vertical and horizontal scaling?
Vertical scaling means upgrading a single server’s CPU, RAM, or storage capacity. Horizontal scaling means adding more servers to distribute load across multiple machines. Vertical scaling is simpler to implement but limited by hardware maximums and creates a single point of failure. Horizontal scaling offers unlimited growth potential and fault tolerance but requires more complex architecture and distributed system management.
Why is observability important for system scalability?
Observability tools provide real-time visibility into system performance, bottlenecks, and error patterns. They enable teams to detect issues proactively before customers experience problems. Without observability, scaling decisions become guesswork, often leading to wasted resources on the wrong solutions. Centralized logging and metrics let you identify actual constraints rather than symptoms.
When should a SaaS company consider moving from a monolith to microservices?
Consider microservices when your modular monolith starts limiting development speed or scaling flexibility. This typically happens when different components have drastically different scaling requirements or when team size makes coordinated deployments a bottleneck. Start with a modular monolith and extract services only when clear benefits justify the operational complexity. Most SaaS companies benefit from delaying microservices until these constraints become real blockers.
What common mistakes cause scalability problems in SaaS?
Delaying scaling decisions until systems are already failing under load creates crisis-driven architecture. Scaling without complete observability data leads to optimizing the wrong components. Neglecting asynchronous processing forces synchronous operations that can’t handle traffic spikes. Tightly coupled services prevent independent scaling of components. Manual deployment processes slow the feedback loop needed for effective scaling iterations.

About the Author
Josh AndersonCo-Founder & CEO at Rule27 Design
Operations leader and full-stack developer with 15 years of experience disrupting traditional business models. I don't just strategize, I build. From architecting operational transformations to coding the platforms that enable them, I deliver end-to-end solutions that drive real impact. My rare combination of technical expertise and strategic vision allows me to identify inefficiencies, design streamlined processes, and personally develop the technology that brings innovation to life.
View Profile

